

Microsoft has developed Magma, a pioneering foundational model capable of comprehending both images and language, marking a significant step forward in multimodal AI. This innovation allows AI agents to execute tasks ranging from navigating user interfaces to controlling robots.
Developed by researchers from Microsoft Research, the University of Maryland, the University of Wisconsin-Madison, and KAIST, alongside the University of Washington, Magma stands as the first foundational model designed to interpret and contextualize multimodal inputs within its environment.
Bridging Verbal and Spatial Intelligence
Magma, which integrates both verbal and spatial intelligence, can formulate plans and execute actions to achieve specified goals. Microsoft highlights that the model extends the capabilities of vision-language (VL) models, preserving their verbal understanding while also enabling them to plan and act in the visual-spatial world. This advancement allows Magma to perform complex agentic tasks, such as UI navigation, and also directly manipulate robots.
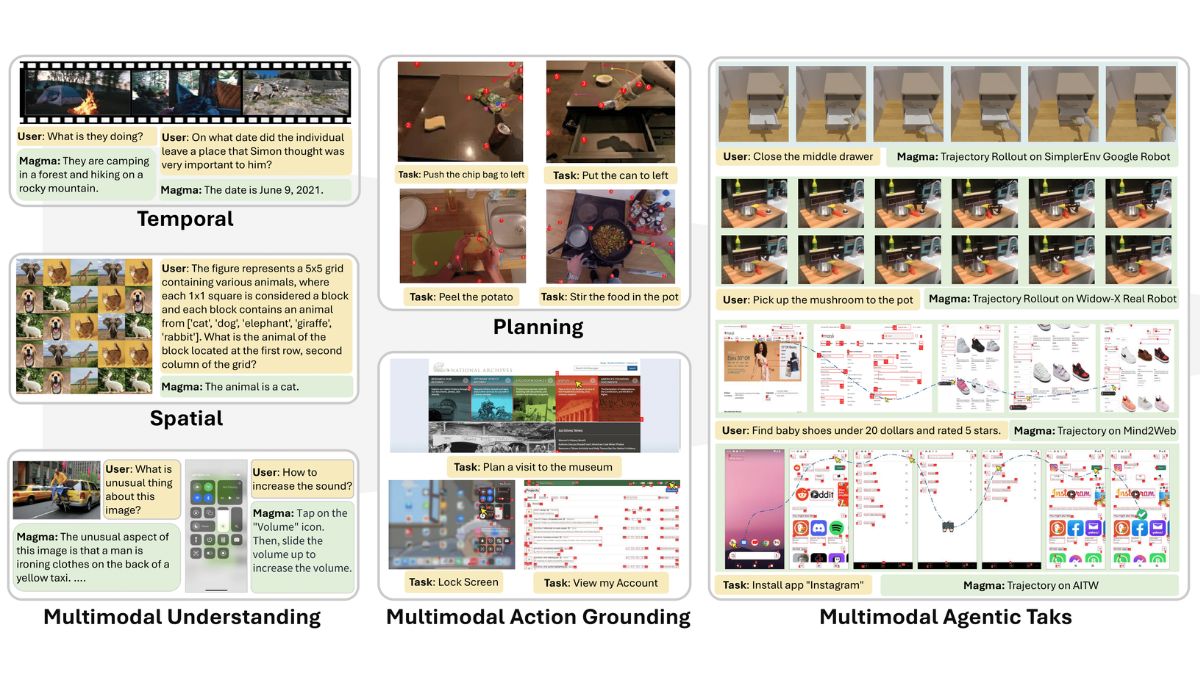
“Magma effectively transfers knowledge from publicly available visual and language data, connecting verbal, spatial, and temporal intelligence to navigate complex tasks and settings,” Microsoft explains.
Training Magma
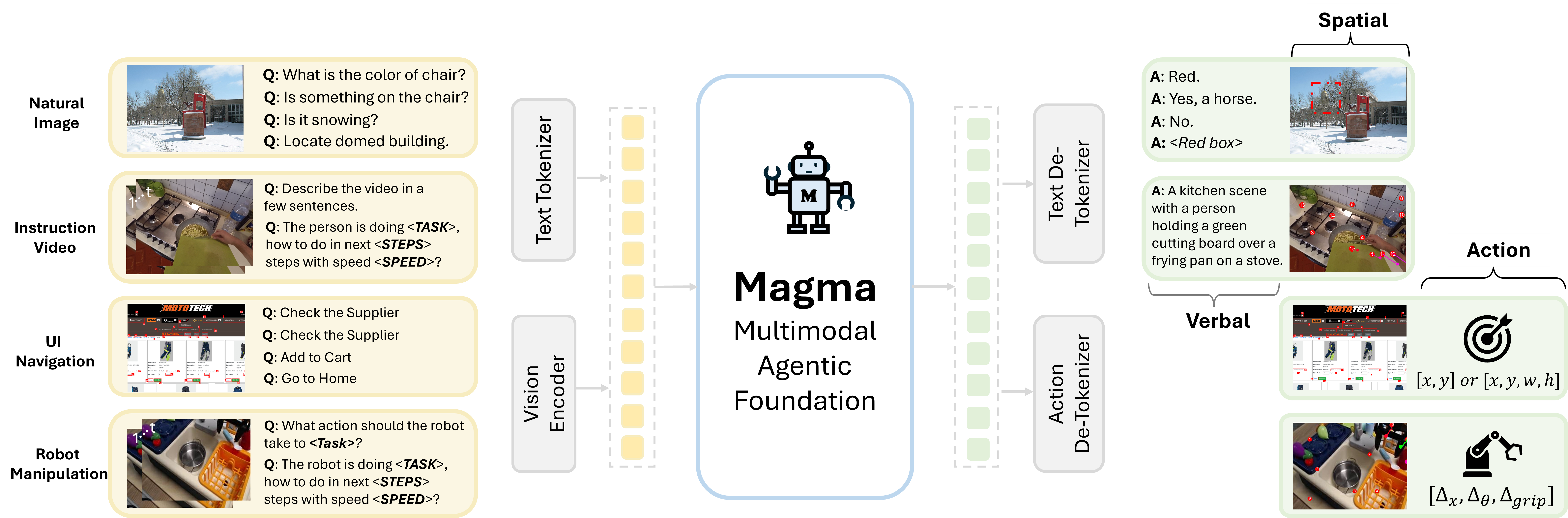
Magma was pre-trained on vast and varied VL datasets that include images, videos, and robotics data. Researchers used a method called Set-of-Mark (SoM) to label actionable items in images – for example, clickable buttons in a graphical user interface. They also used Trace-of-Mark (ToM) to label movements in videos, such as the trajectory of a robotic arm.
What sets Magma apart is its acquisition of spatial intelligence, learned from extensive training data through SoM and ToM. Microsoft reports that Magma achieves new state-of-the-art results in tasks such as UI navigation and robotic manipulation, outperforming previous models that are specifically designed for these tasks.
“On VL tasks, Magma also compares favorably to popular VL models that are trained on much larger datasets,” Microsoft adds.
To train Magma, researchers divided the text into smaller units (tokens). Images and videos from different sources were encoded by a shared vision encoder, which converted visual information into a format the model could understand. These discrete and continuous tokens are then inputted into a large language model (LLM) to generate outputs in verbal, spatial, and action formats.

SoM is used to ground actions across diverse data types. In the image above, SoM prompting enables effective action grounding in images for UI screenshots (left), robot manipulation (middle), and human video (right) by having the model predict numeric marks for clickable buttons or robot arms in image space.

ToM specifically helps in labelling and understanding movements in videos and robotics data. The above image shows ToM supervisions for robot manipulation (left) and human action (right). This helps the model comprehend video dynamics and anticipate future states before acting while using fewer tokens than next-frame prediction to capture action-related dynamics.
Real-World Capabilities
Microsoft also presented a zero-shot evaluation of Magma’s agentic intelligence, emphasizing its ability to conduct a complete set of tasks. In UI navigation, the model successfully performed actions like checking the weather, enabling flight mode, sharing files, and texting specific individuals.
in robot manipulation, Microsoft claims that Magma consistently outperformed OpenVLA (finetuning) in soft object manipulation and pick-and-place operations. The model demonstrated reliable performance in both in-distribution and out-of-distribution generalization tasks on real robots.
In spatial reasoning assessments, Microsoft notes that Magma surpasses GPT-4o, answering spatial reasoning questions relatively well, despite using less pretraining data. Furthermore, in multimodal understanding, Magma performed competitively and even outperformed some state-of-the-art approaches, like Video-Llama2 and ShareGPT4Video, on most benchmarks despite using less video instruction tuning data.