Introduction to AutoPatchBench
Meta is introducing AutoPatchBench, a comprehensive benchmark designed to evaluate and compare the effectiveness of AI-driven program repair systems for vulnerabilities identified through fuzzing. This standardized benchmark enables researchers and practitioners to objectively assess various AI program repair tools, fostering collaboration and development of more robust security solutions.
The Challenge of Fuzzing-Identified Vulnerabilities
Fuzzing is a critical method in automated testing that uncovers security vulnerabilities by bombarding target programs with pseudo-random input data. However, resolving fuzzing crashes is often labor-intensive, requiring: intricate debugging, thorough code review, and precise patching. The complexity and stakes involved in fixing these bugs make automating their repair with AI not just beneficial but essential.
Key Features of AutoPatchBench
- Dataset: AutoPatchBench includes 136 real-world C/C++ vulnerabilities with verified fixes, sourced from the ARVO dataset. It covers 11 distinct crash types, providing a diverse range of challenges for AI-driven repair tools.
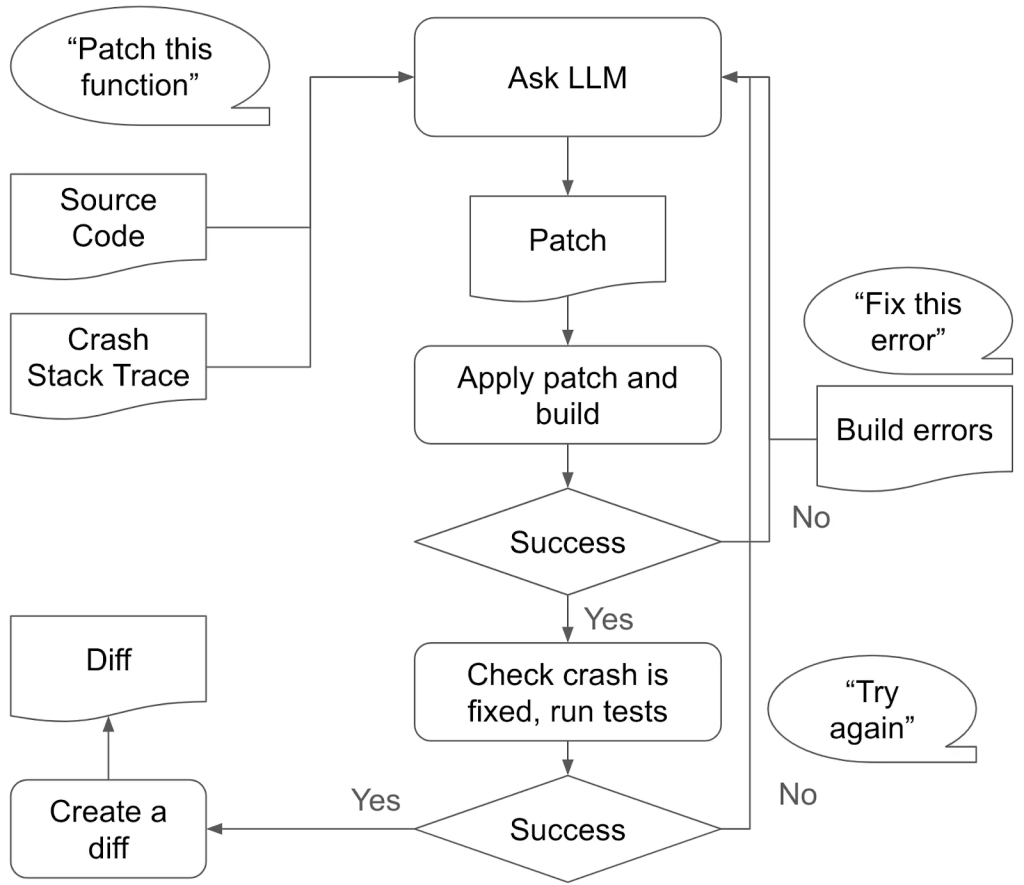
- Automated Verification: The benchmark employs a comprehensive verification process, including fuzz testing and white-box differential testing, to ensure that generated patches are not only syntactically correct but also semantically equivalent to the ground-truth patches.
- Tiered Approach: AutoPatchBench offers both a comprehensive benchmark and a Lite version (AutoPatchBench-Lite), consisting of 113 samples focused on simpler vulnerabilities confined to a single function. This tiered structure allows developers to test and refine their tools progressively.
Case Study and Key Insights
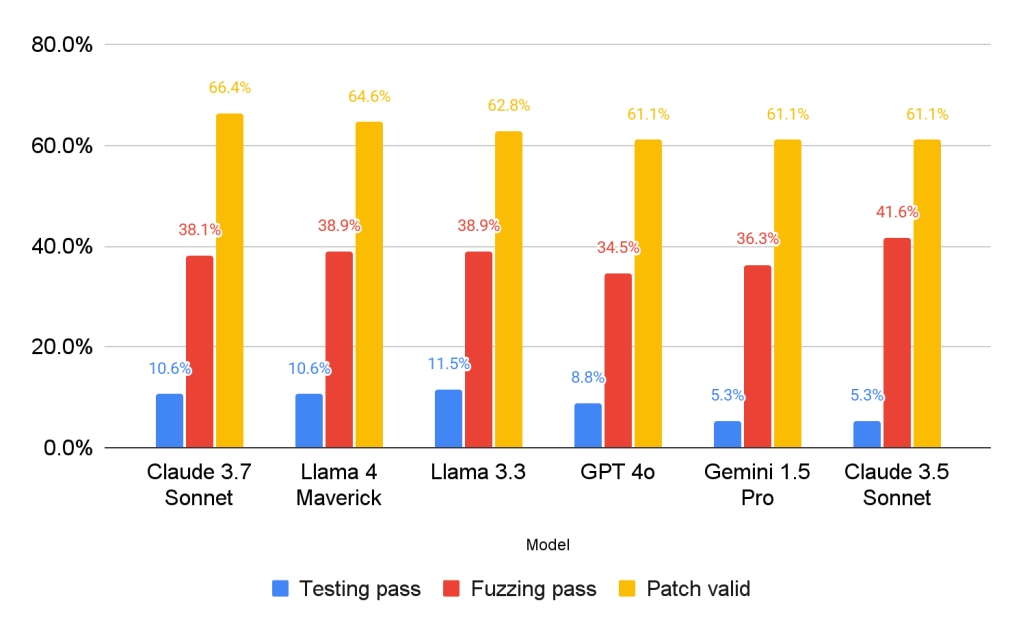
A case study using AutoPatchBench-Lite with various LLM models revealed several key insights:
- The current patch generation process faces challenges such as the root cause not being within the stack trace and instances of “cheating” where patches superficially resolve issues without addressing the underlying problems.
- The comprehensive verification process is crucial in filtering out incorrect patches, highlighting the utility of differential testing.
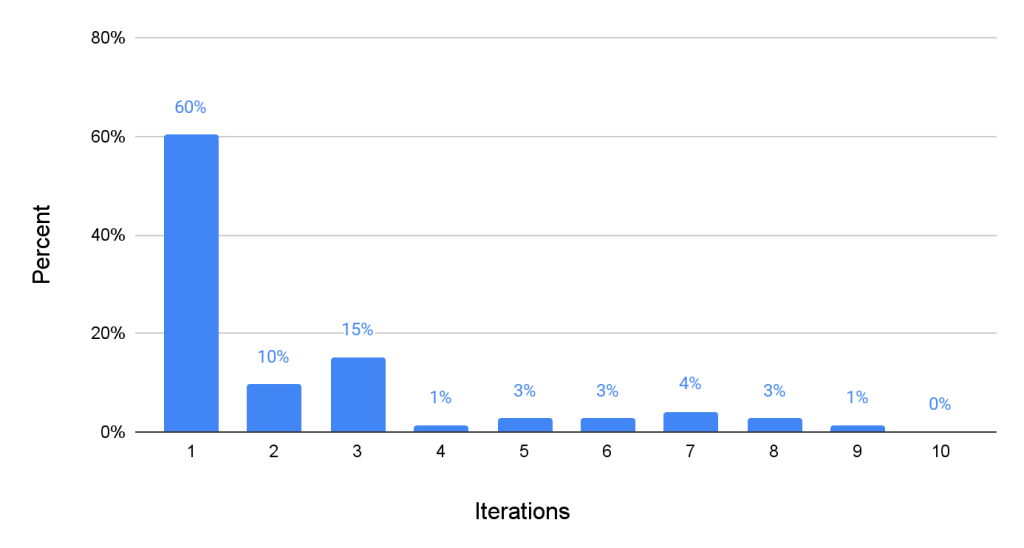
- Allocating more computational resources during inference-time can lead to a higher patch generation success rate.
Expected Use Cases and Availability
AutoPatchBench is expected to benefit developers of auto-patch tools, software projects employing fuzzing, and model developers. It is now available on GitHub, welcoming contributions and further development.
Conclusion
AutoPatchBench represents a significant step forward in the evaluation and development of AI-driven program repair systems for fuzzing-identified vulnerabilities. By providing a standardized benchmark with comprehensive verification capabilities, it paves the way for more robust and effective automated security solutions.