Introduction
The application of digital technologies, such as artificial intelligence, to improve medical management and healthcare delivery is known as digital medicine. A significant challenge in this field is the need for large datasets to train deep learning (DL) models, which is often problematic due to patient data privacy concerns.
Challenges in Medical Data Collection
Medical data, stored as Electronic Health Records (EHRs), contains sensitive patient information. Regulations like the European Union’s artificial intelligence regulation aim to reduce data abuse and ensure governance over developers. These restrictions make it difficult to prepare large, fair datasets for training DL models.
Synthetic Health Records (SHRs)
A practical solution to this challenge is creating synthetic copies of clinical datasets, known as Synthetic Health Records (SHRs). SHRs resemble EHR data characteristics while keeping subjects unidentifiable. They can be used for research purposes, training, and validation of DL models.
Review Methodology
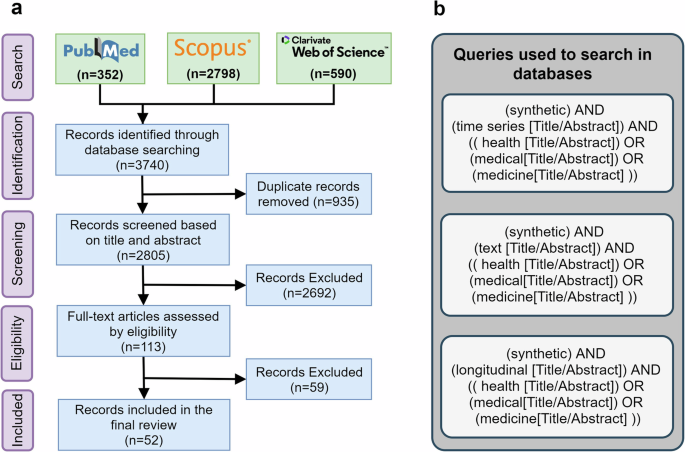
This scoping review followed the PRISMA-ScR guidelines and searched PubMed, Web of Science, and Scopus for relevant publications between 2018 and 2023. The review included 52 publications that addressed machine learning topics for EHR generation.
Findings
The review found that:
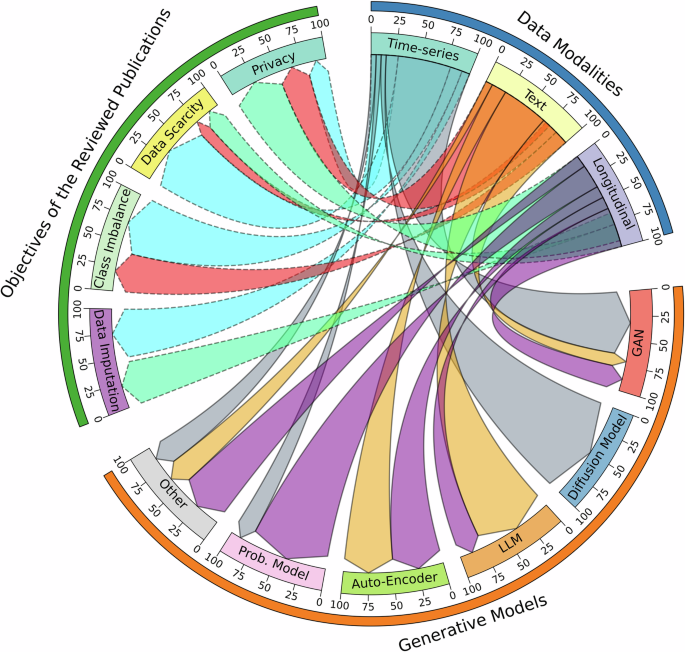
- Generative Adversarial Networks (GANs) were predominantly used for generating medical time series data.
- Large Language Models (LLMs) were widely used for generating synthetic medical texts.
- Probabilistic models were mainly used for longitudinal data.
- GAN-based models suffered from mode collapse and required preliminary experiments to identify optimal hyperparameters.
- Diffusion models showed promising results in synthesizing time series data but faced challenges like computational costs and interoperability difficulties.
Challenges and Future Directions
Key challenges include:
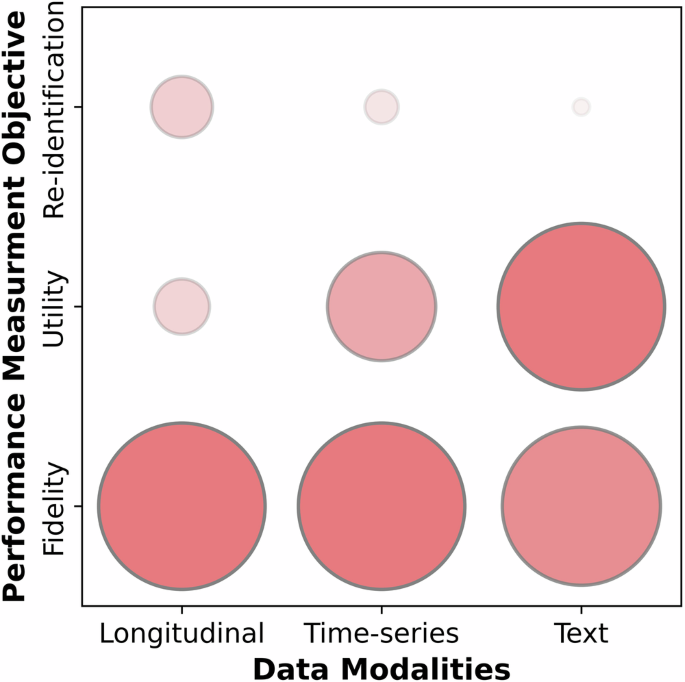
- Lack of generic methods and metrics for comparing generative model performance.
- Inadequate evaluation of re-identification risks in SHRs.
- Limited representation of non-acute medical conditions and diverse demographic groups in public datasets.
- Need for integrating domain-specific expertise from physicians into the learning process.
Conclusion
Generating SHRs is a practical strategy for addressing data scarcity and privacy concerns in digital medicine. The field is evolving, with a shift from GAN-based methods to statistical models like graph neural networks and diffusion models. Future research should focus on developing standardized evaluation metrics and improving the utility and fidelity of SHRs.